#获取页面 defurl(page): url = "https://www.doutula.com/photo/list/?page="+str(page) headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"} response = requests.get(url,headers=headers) form = parsel.Selector(response.text) all_imformation = form.xpath("//a[@class='col-xs-6 col-sm-3']") get_link(all_imformation) #爬取图片内容 defget_link(all_imformation): for i in all_imformation: photo_name = i.xpath('./img[@referrerpolicy="no-referrer"]/@alt').get() photo_src = i.xpath('./img[@referrerpolicy="no-referrer"]/@data-original').get() bin_data = requests.get(photo_src,headers=headers).content photo_last = photo_src.split(".")[-1] save(photo_name,photo_last,bin_data) #保存图片 defsave(photo_name,photo_last,bin_data): with open("./picture/"+photo_name+"."+photo_last,"wb") as fl: fl.write(bin_data)
线程处理:
定义一个main函数,用到进程
1 2 3 4 5 6 7
if __name__ =="__main__": thread = int(input("请输入线程数:")) li = [i for i in range(1,10)] for i in range(1,thread): thread=threading.Thread(target=url,args=(li[0],)) thread.start() li.pop(0)
import requests,parsel,threading #获取页面 defurl(page): url = "https://www.doutula.com/photo/list/?page="+str(page) headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"} response = requests.get(url,headers=headers) form = parsel.Selector(response.text) all_imformation = form.xpath("//a[@class='col-xs-6 col-sm-3']") get_link(all_imformation,headers) #爬取图片内容 defget_link(all_imformation,headers): for i in all_imformation: photo_name = i.xpath('./img[@referrerpolicy="no-referrer"]/@alt').get() photo_src = i.xpath('./img[@referrerpolicy="no-referrer"]/@data-original').get() bin_data = requests.get(photo_src,headers=headers).content photo_last = photo_src.split(".")[-1] save(photo_name,photo_last,bin_data) #保存图片 defsave(photo_name,photo_last,bin_data): with open("./picture/"+photo_name+"."+photo_last,"wb") as fl: fl.write(bin_data) if __name__ =="__main__": thread = int(input("请输入线程数:")) li = [i for i in range(1,10)] for i in range(1,thread): thread=threading.Thread(target=url,args=(li[0],)) thread.start() li.pop(0)
defpage(li): lock.acquire() if len(li)==0: return get_page=li[0] li.pop(0) lock.release() page(li) url(get_page) defurl(page): print("============下载第{page}页=============".format(page=page)) url = "https://www.doutula.com/photo/list/?page="+str(page) headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"} response = requests.get(url,headers=headers) form = parsel.Selector(response.text) all_imformation = form.xpath("//a[@class='col-xs-6 col-sm-3']") get_link(all_imformation,headers) print("============第{page}页下载完成=============".format(page=page))
defget_link(all_imformation,headers): for i in all_imformation: photo_name = i.xpath('./img[@referrerpolicy="no-referrer"]/@alt').get() photo_src = i.xpath('./img[@referrerpolicy="no-referrer"]/@data-original').get() bin_data = requests.get(photo_src,headers=headers).content photo_last = photo_src.split(".")[-1] save(photo_name,photo_last,bin_data) defsave(photo_name,photo_last,bin_data): with open("./picture/"+photo_name+"."+photo_last,"wb") as fl: fl.write(bin_data)
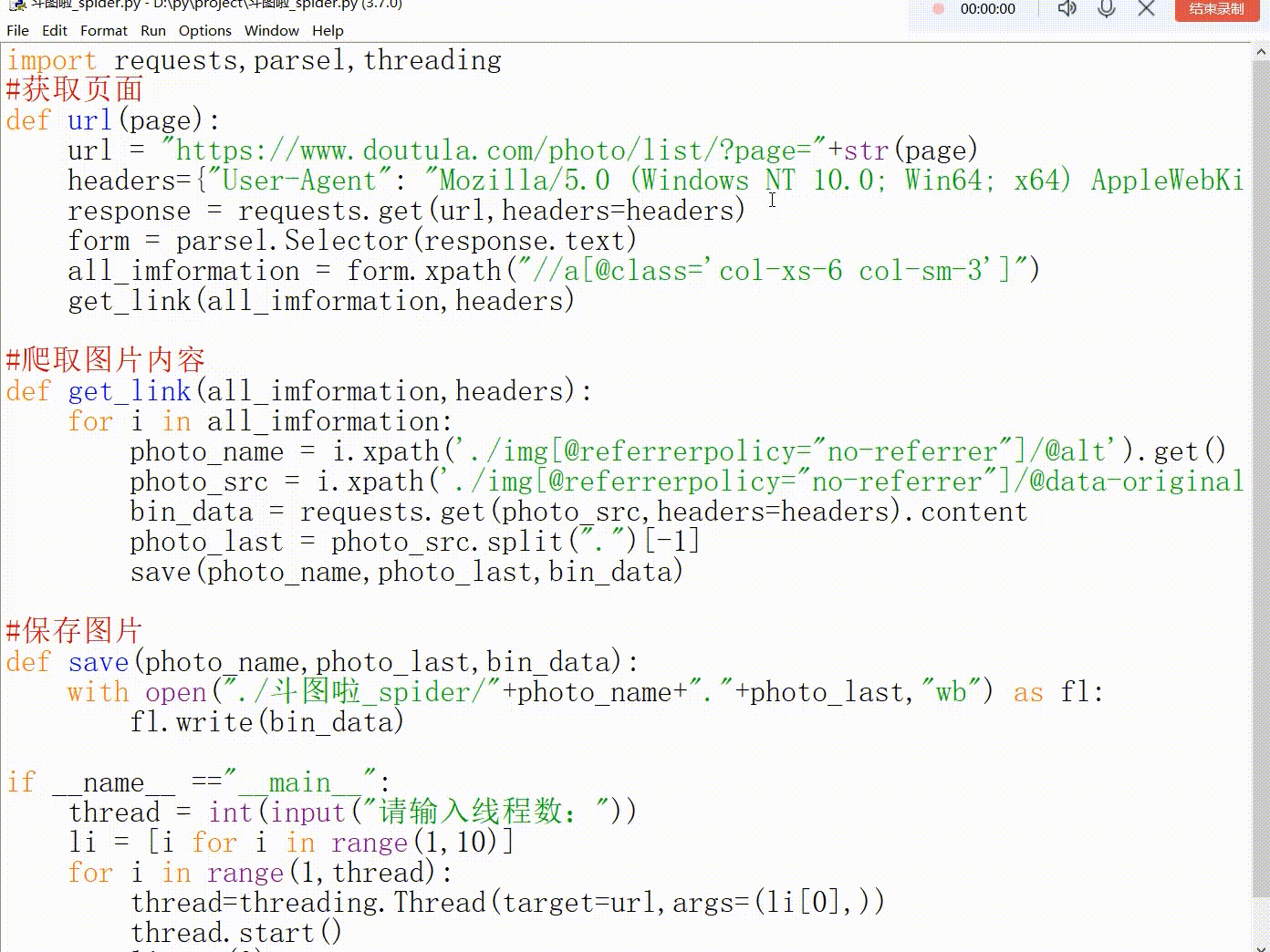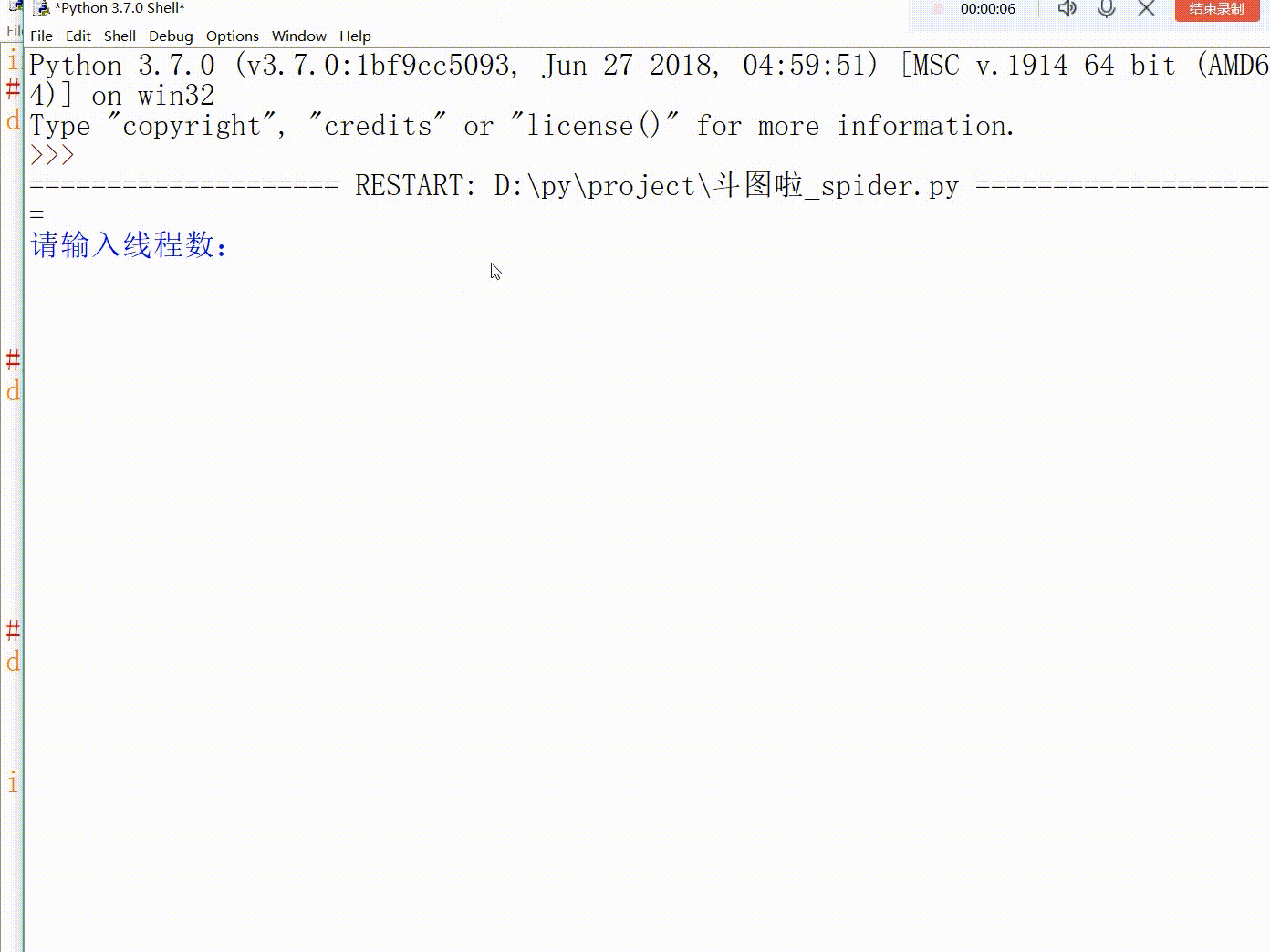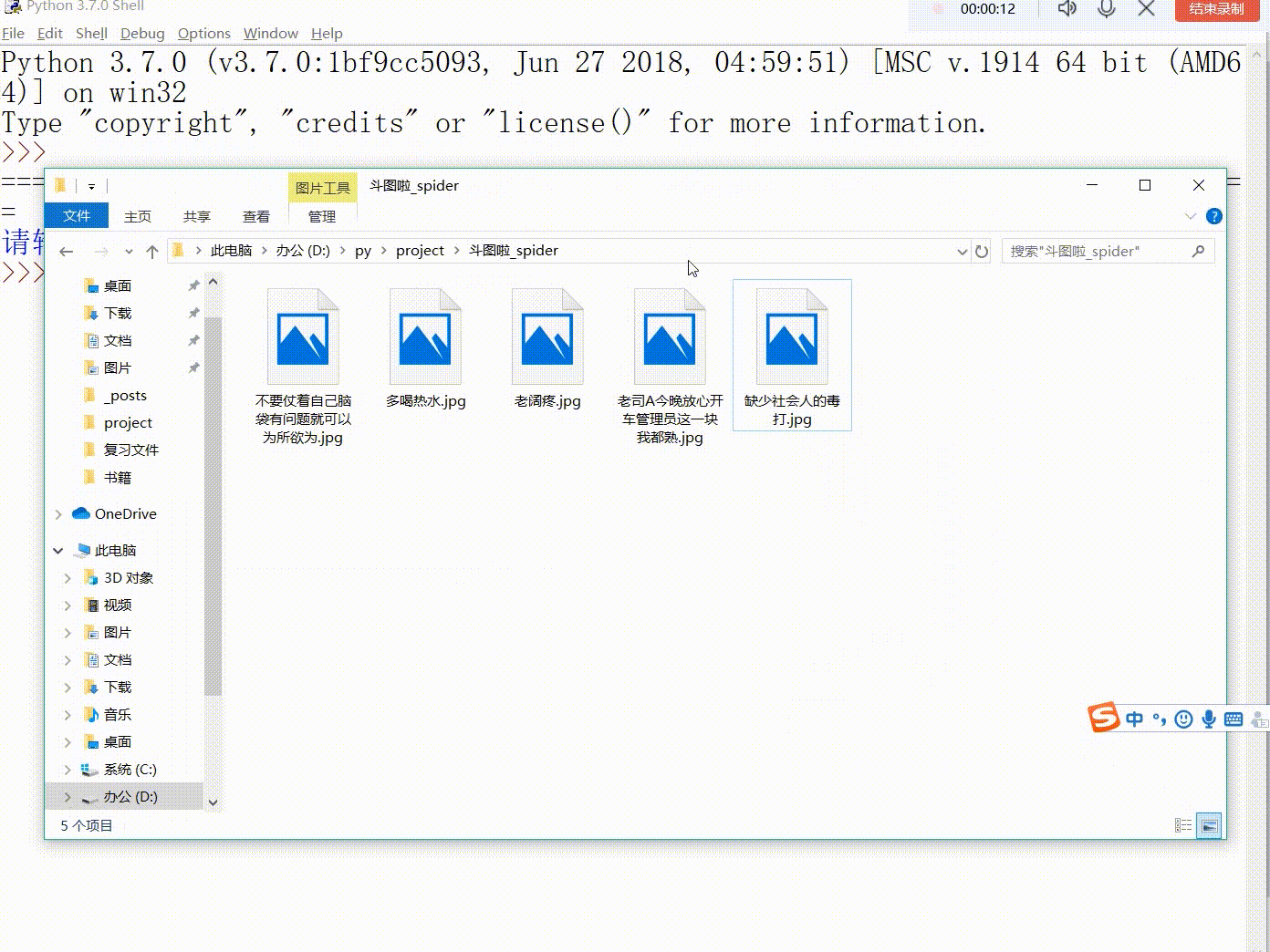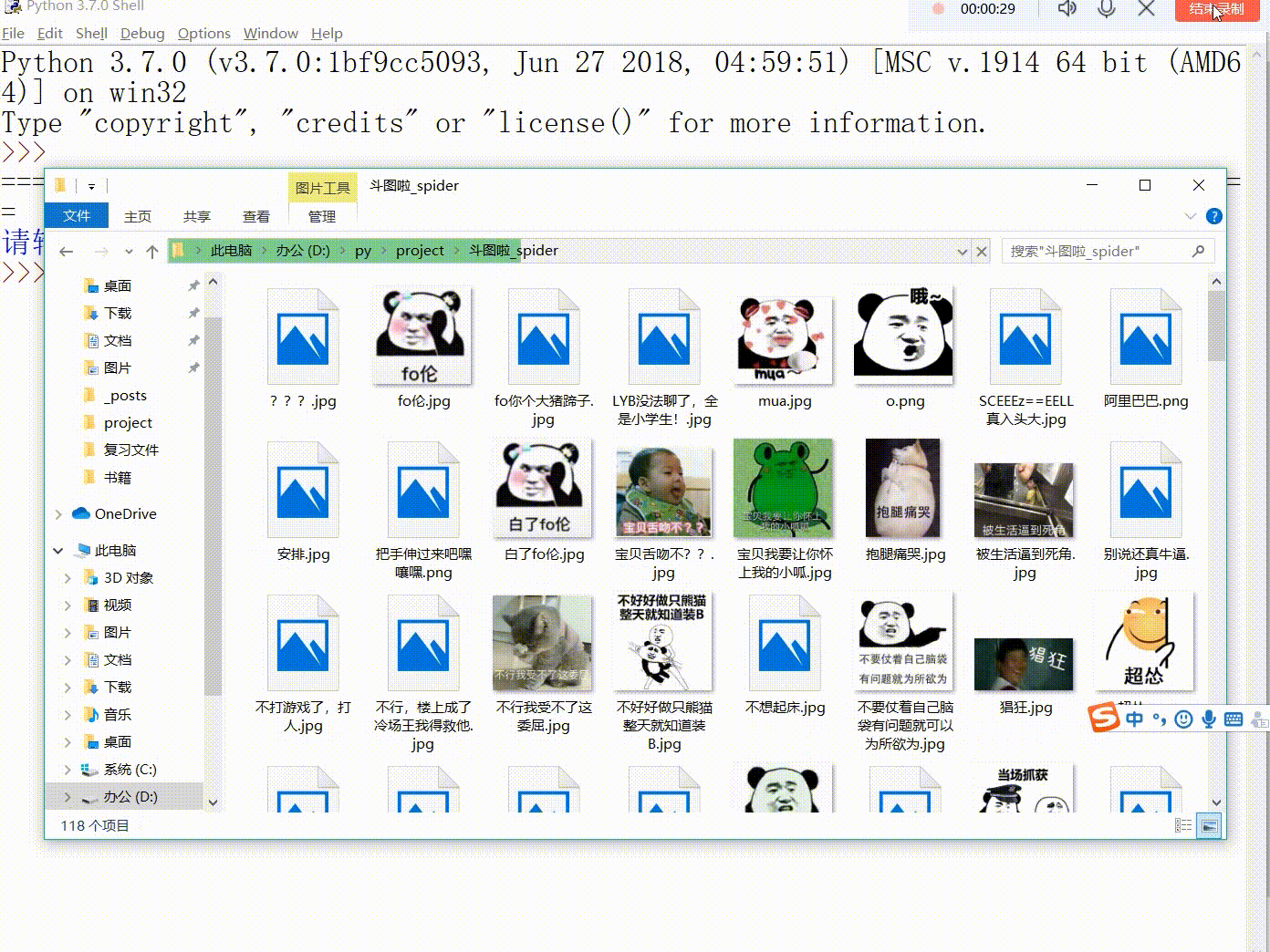
li=[] lock = threading.Lock() if __name__ =="__main__": thread = int(input("请输入线程数:")) pages = int(input("请输入需要爬取的页数:")) li=[i for i in range(1,pages+1)] for i in range(1,thread): thread=threading.Thread(target=page,args=(li,)) thread.start()
for i in all_tr: ip = i.xpath("./td[1]/text()").get() port = i.xpath("./td[2]/text()").get() method = i.xpath("./td[4]/text()").get() print(method,ip,port)
li=[] for i in all_tr: ip = i.xpath("./td[1]/text()").get() port = i.xpath("./td[2]/text()").get() method = i.xpath("./td[4]/text()").get() dic={} dic[method]=ip+":"+port li.append(dic) print(li)
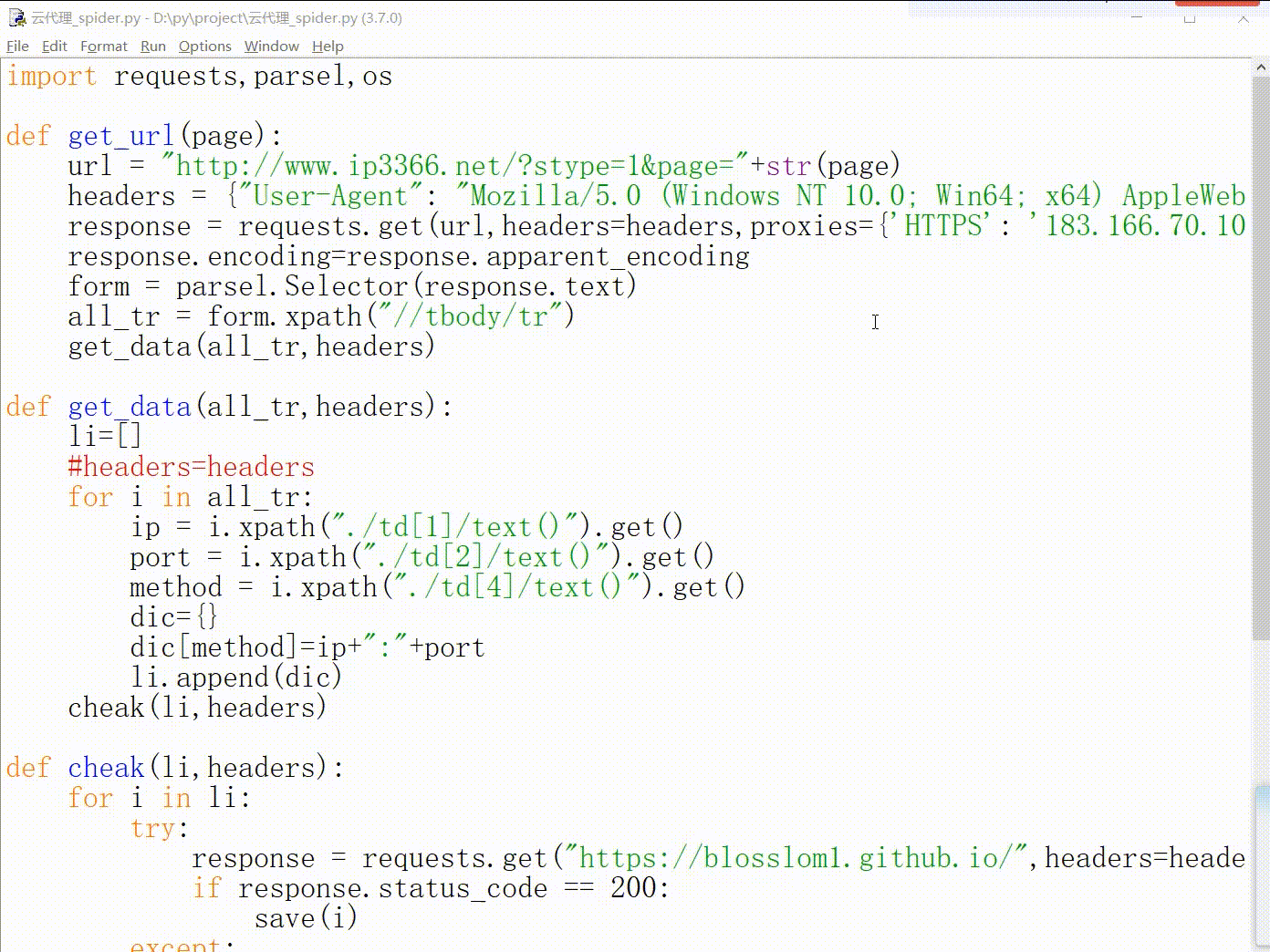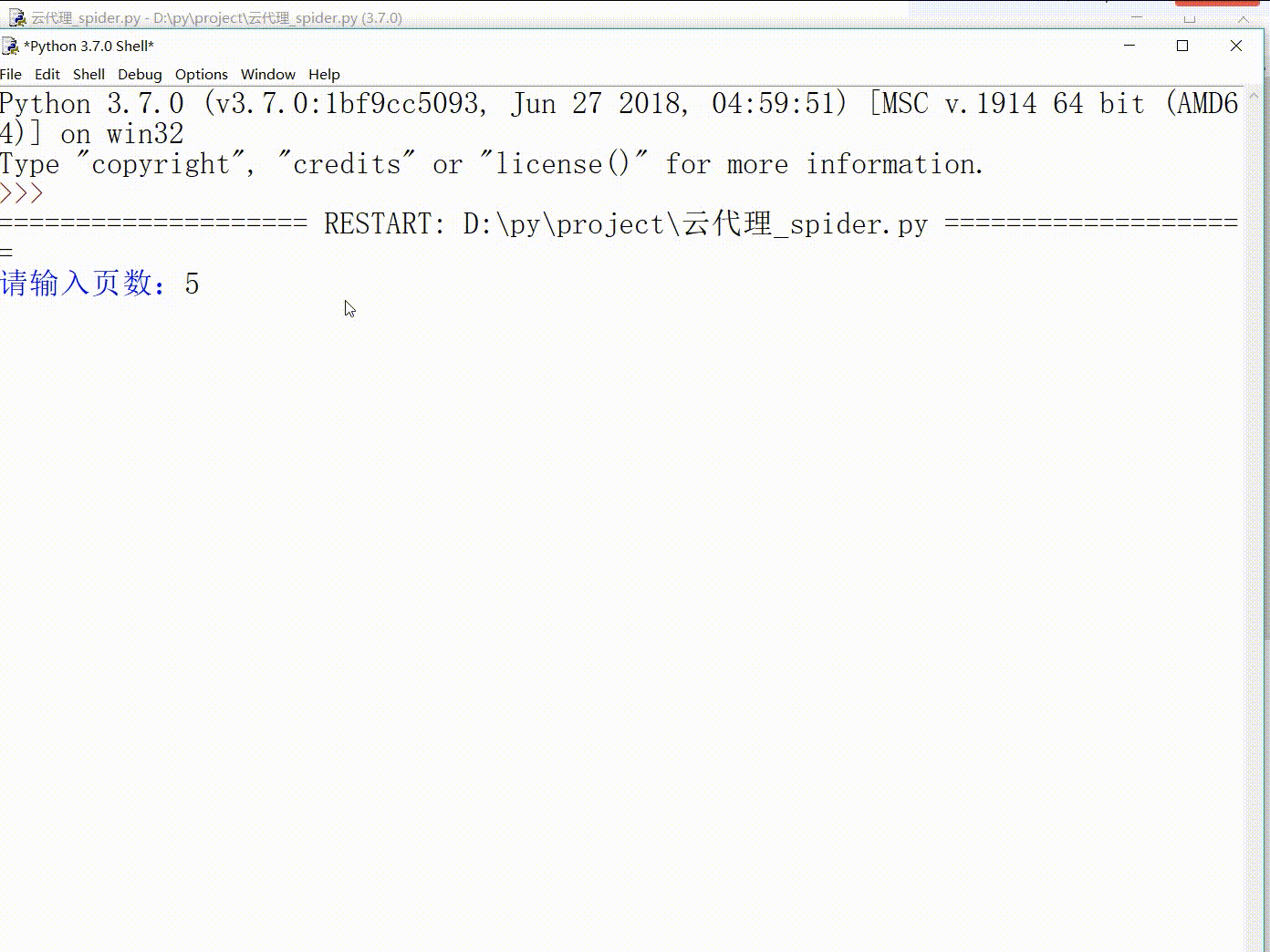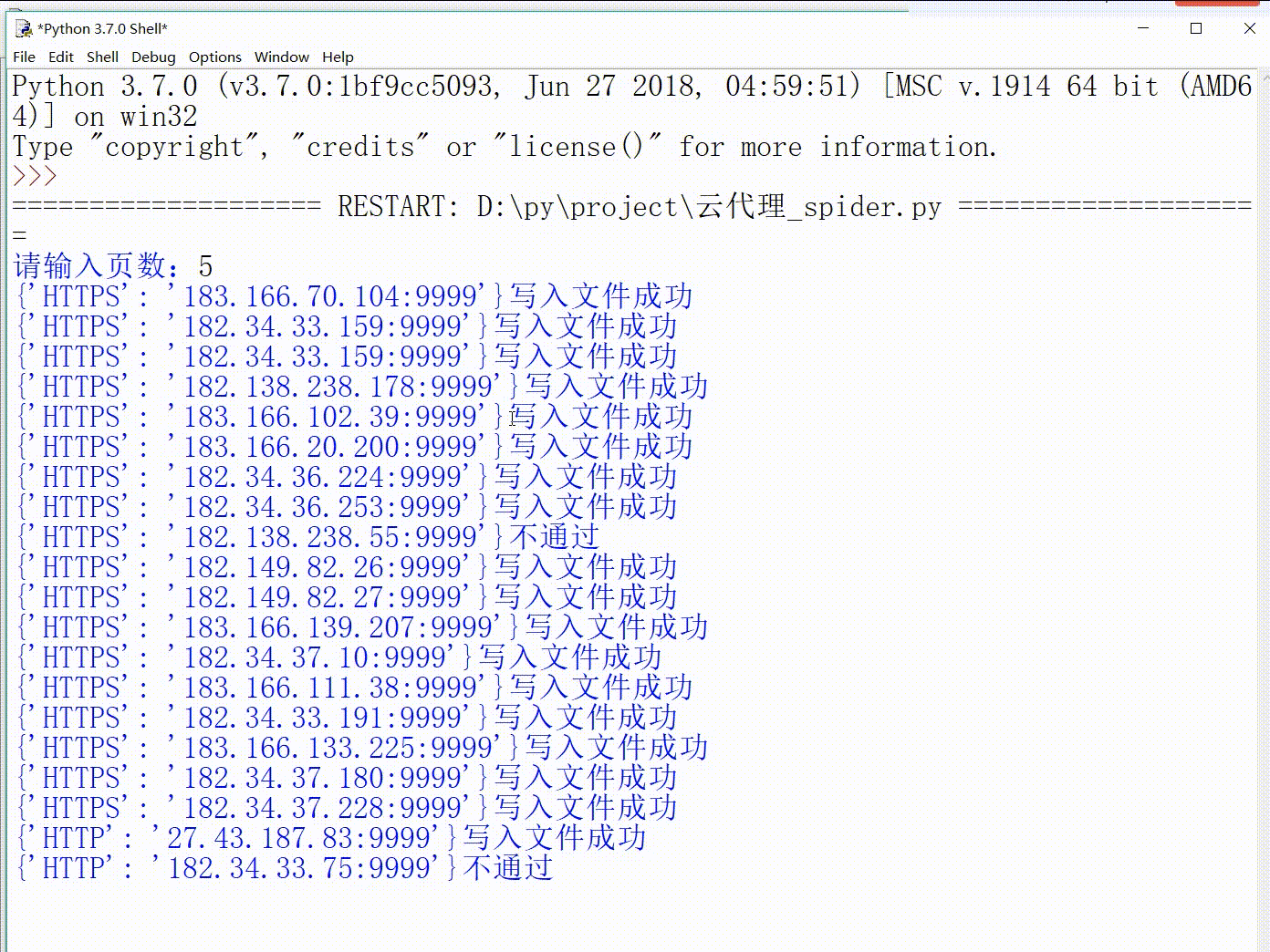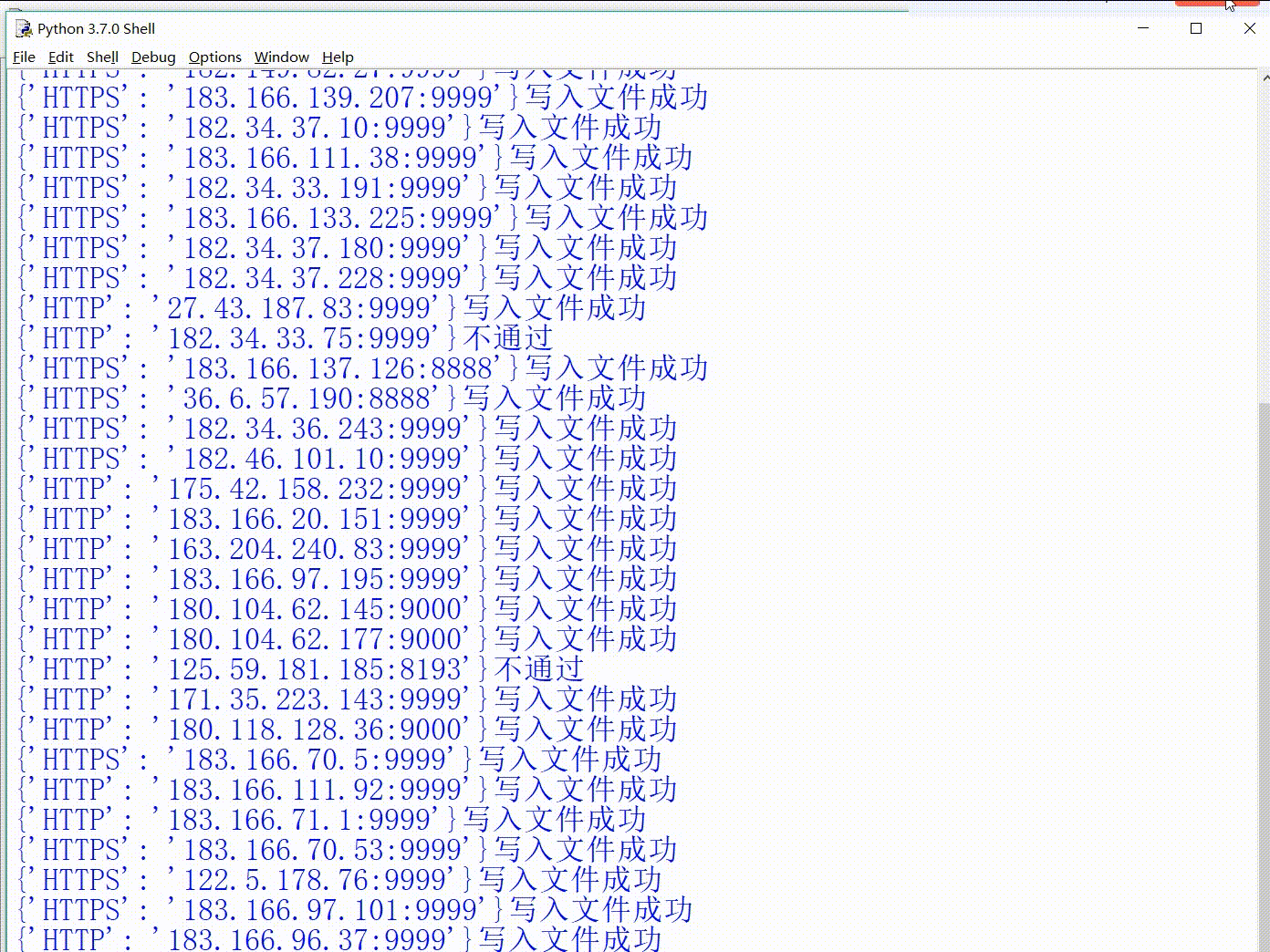
defget_url(page): url = "http://www.ip3366.net/?stype=1&page="+str(page) headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"} response = requests.get(url,headers=headers) response.encoding=response.apparent_encoding form = parsel.Selector(response.text) all_tr = form.xpath("//tbody/tr") get_data(all_tr)
defget_data(all_tr): li=[] for i in all_tr: ip = i.xpath("./td[1]/text()").get() port = i.xpath("./td[2]/text()").get() method = i.xpath("./td[4]/text()").get() dic={} dic[method]=ip+":"+port li.append(dic) print(li) if __name__ == "__main__": for i in range(1,5): get_url(i)
defcheak(li,headers): for i in li: response = requests.get("https://blosslom1.github.io/",headers=headers,proxies=i,timeout=1) print(response)
访问成功过输出<Response [200]>,但是很多情况会超时,程序就会报错所有使用try
1 2 3 4 5 6 7 8 9 10
defcheak(li,headers): for i in li: try: response = requests.get("https://blosslom1.github.io/",headers=headers,proxies=i,timeout=0.1) if response.status_code==200: save() except: print(str(i)+"不通过") else: print(str(i)+"写入文件成功")
最后将数据写入文件,需要使用os判断文件夹是否存在,如不存在新建一个文件夹,然后创建文件写入数据。
1 2 3 4 5 6 7
defsave(i): exist_dir = os.access("./云代理",os.F_OK) ifnot(exist_dir): os.mkdir("./云代理") with open("./云代理/IP.txt","a") as fl: fl.write(str(i)) fl.write("\n")
defget_url(page): url = "http://www.ip3366.net/?stype=1&page="+str(page) headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"} response = requests.get(url,headers=headers) response.encoding=response.apparent_encoding form = parsel.Selector(response.text) all_tr = form.xpath("//tbody/tr") get_data(all_tr,headers)
defget_data(all_tr,headers): li=[] #headers=headers for i in all_tr: ip = i.xpath("./td[1]/text()").get() port = i.xpath("./td[2]/text()").get() method = i.xpath("./td[4]/text()").get() dic={} dic[method]=ip+":"+port li.append(dic) cheak(li,headers)
defcheak(li,headers): for i in li: try: response = requests.get("https://blosslom1.github.io/",headers=headers,proxies=i,timeout=1) if response.status_code == 200: save(i) except: print(str(i)+"不通过") else: print(str(i)+"写入文件成功")
defsave(i): exist_dir = os.access("./云代理",os.F_OK) ifnot(exist_dir): os.mkdir("./云代理") with open("./云代理/IP.txt","a") as fl: fl.write(str(i)) fl.write("\n")
if __name__ == "__main__": page = int(input("请输入页数:")) for i in range(1,page): get_url(i)
ping = IP(dst=ip,id=ip_id)/ICMP(id=icmp_id,seq=seq)/b"who are you" response = sr1(ping,verbose=0,timeout=2) if response != None: print("{ip} 存活".format(ip=ip))
if __name__=="__main__": print(" //^^^^^^))") print(" // ))") print(" //======))") print(" // ") print(" // ") print("// ——Blosslom") try: get_ip = sys.argv[1] all_ip = ipaddress.ip_network(get_ip) print("正在扫描"+str(all_ip)+"网段") for ip in all_ip: thread = threading.Thread(target=ping,args=(str(ip),)) thread.start() except: print("输入错误请检查输入") print("网段需要类似192.168.0.0/24以0结尾") time.sleep(1) print("进程退出")
defarp(ip): arp = Ether(dst="FF:FF:FF:FF:FF:FF")/ARP(pdst=ip)/b"who are you" response = srp1(arp,verbose=0,timeout=1) if response != None: print("{ip} 存活".format(ip=ip))
defget_local_ip(): try: s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) s.connect(('www.baidu.com', 80)) ip = s.getsockname()[0] finally: s.close() return ip
deftcp(ip,start_port,end_port): ip_id = random.randint(0,65535) tcp_seq = random.randint(0,4294967295) tcp_sport = random.randint(0,1000) tcp = IP(id=ip_id,dst=ip)/TCP(dport=(int(start_port),int(end_port)),seq=tcp_seq) #tcp = [i for i in tcp] response = [i if i[1].haslayer(TCP) and i[1].getlayer(TCP).fields['flags']==18 \ elseNonefor i in list(filter(None,[sr1(j,verbose=0,timeout=0.1) \ for j in [k for k in tcp]]))] response = list(filter(None,response)) if response: for i in response: target_ip = i[0].getlayer(IP).fields["src"] sport=i[1].getlayer(TCP).fields['sport'] print(str(target_ip)+"端口|"+str(sport)+"|开放") print("========================")
if __name__=="__main__": print("===============") print(" || ))") print(" ||\ ==】)") print(" TCP TCP -\\\\]") print(" ||") print(" || ——Blosslom") try: get_ip = sys.argv[1] all_ip = ipaddress.ip_network(get_ip) get_start_port = sys.argv[2] get_end_port = sys.argv[3] print("正在扫描"+str(all_ip)+"网段的"+str(get_start_port)+" to "+str(get_end_port)+"端口") for ip in all_ip: thread = threading.Thread(target=tcp,args=(str(ip),get_start_port,get_end_port,)) thread.start() time.sleep(1) print("进程退出") print("处理数据......") except: print("输入错误请检查输入") print("输入格式为 IP 起始端口 结束端口") print("例如:tcp.py 8.8.8.0/24 1 100")